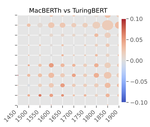
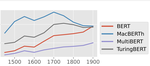
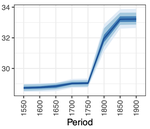
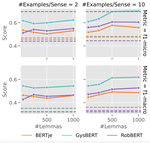
Focusing on the domain of historical text in English, this paper demonstrates that pre-training on domain-specific (i.e. historical) data from scratch yields a generally stronger background model than adapting a present-day language model.
We show this on the basis of a variety of downstream tasks, ranging from established tasks such as Part-of-Speech tagging, Named Entity Recognition and Word Sense Disambiguation, to ad-hoc tasks like Sentence Periodization, which are specifically designed to test historically relevant processing.