MacBERTh and GysBERT models
How to cite:
-
MacBERTh (English): When using the English model (MacBERTh), please cite the following paper (BibTeX can be found using the ‘cite’ button in ‘Project Publications’):
- Manjavacas, Enrique & Lauren Fonteyn. 2022. Adapting vs. Pre-training Language Models for Historical Languages. Journal of Data Mining & Digital Humanities jdmdh:9152. https://doi.org/10.46298/jdmdh.9152
-
GysBERT (Dutch): When using the Dutch model (GysBERT), please cite the following paper (BibTeX can be found using the ‘cite’ button in ‘Project Publications’):
- Manjavacas, Enrique & Lauren Fonteyn. 2022. Non-Parametric Word Sense Disambiguation for Historical Languages. Proceedings of the 2nd International Workshop on Natural Language Processing for Digital Humanities (NLP4DH), 123-134. Association for Computational Linguistics. https://aclanthology.org/2022.nlp4dh-1.16
MacBERTh and GysBERT are language models (more specifically, BERT models) pre-trained on historical textual material (date range: 1450-1950).
Researchers who interpret and analyse historical textual material are well-aware that languages are subject to change over time, and that the way in which concepts and discourses of class, gender, norms and prestige function in different time periods. As such, it is quite important that the interpretation of textual/linguistic material from the past is not approached from a present-day point-of-view, which is why NLP models pre-trained on present-day language data are less than ideal candidates for the job. That’s where our historical models can help.
MacBERTh, a model pre-trained on historical English (1450-1950), has been published in the huggingface repository. GysBERT, a model pre-trained on historical Dutch (1500-1950), has been published in the huggingface repository.
Past & Upcoming Talks




Project Publications
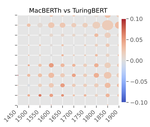
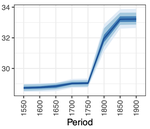
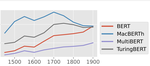
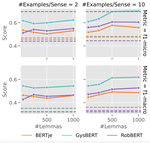
Related Publications
The following teams have used and evaluated MacBERTh:
- Iiro Rastas, Yann Ryan, Iiro Tiihonen, Mohammadreza Qaraei, Liina Repo, Rohit Babbar, Eetu Mäkelä, Mikko Tolonen, Filip Ginter. 2022. Explainable Publication Year Prediction of Eighteenth Century Texts with the BERT Model. Proceedings of the 3rd Workshop on Computational Approaches to Historical Language Change, 68 - 77.
- S. Menini, T. Paccosi, S. Tonelli, M. Van Erp, I. Leemans, P. Lisena, R. Troncy, W. Tullett, A. Hürriyetoglu, G. Dijkstra, F. Gordijn, E. Jürgens, J. Koopman, A. Ouwerkerk, S. Steen, I. Novalija, J. Brank, D. Mladenic, A. Zidar. 2022. A Multilingual Benchmark to Capture Olfactory Situations over Time. Proceedings of the 3rd Workshop on Computational Approaches to Historical Language Change, 1 - 10.
- Massri, M. Besher, Inna Novalija, Dunja Mladenić, Janez Brank, Sara Graça da Silva, Natasza Marrouch, Carla Murteira, Ali Hürriyetoğlu, and Beno Šircelj. 2022. Harvesting Context and Mining Emotions Related to Olfactory Cultural Heritage. Multimodal Technologies and Interaction 6(7): 57.